2 minutes
Web crawling
December started with me looking into web crawling. I managed to set up the Heritrix web crawler, which as the Github README reads -
Heritrix is the Internet Archive’s open-source, extensible, web-scale, archival-quality web crawler project. Heritrix (sometimes spelled heretrix, or misspelled or missaid as heratrix/heritix/heretix/heratix) is an archaic word for heiress (woman who inherits). Since our crawler seeks to collect and preserve the digital artifacts of our culture for the benefit of future researchers and generations, this name seemed apt.
It is Linux only, so I had to run it from the Windows Subsystem for Linux via Ubuntu and also install Java to get it running. I got it all configured and I was able to crawl and capture a website, the website being The Royal Institute of Philosophy. The capture is displayed via pywb, a “Python Web Archiving Toolkit for replay and recording of web archives”, i.e. a Python implementation of the Wayback Machine -
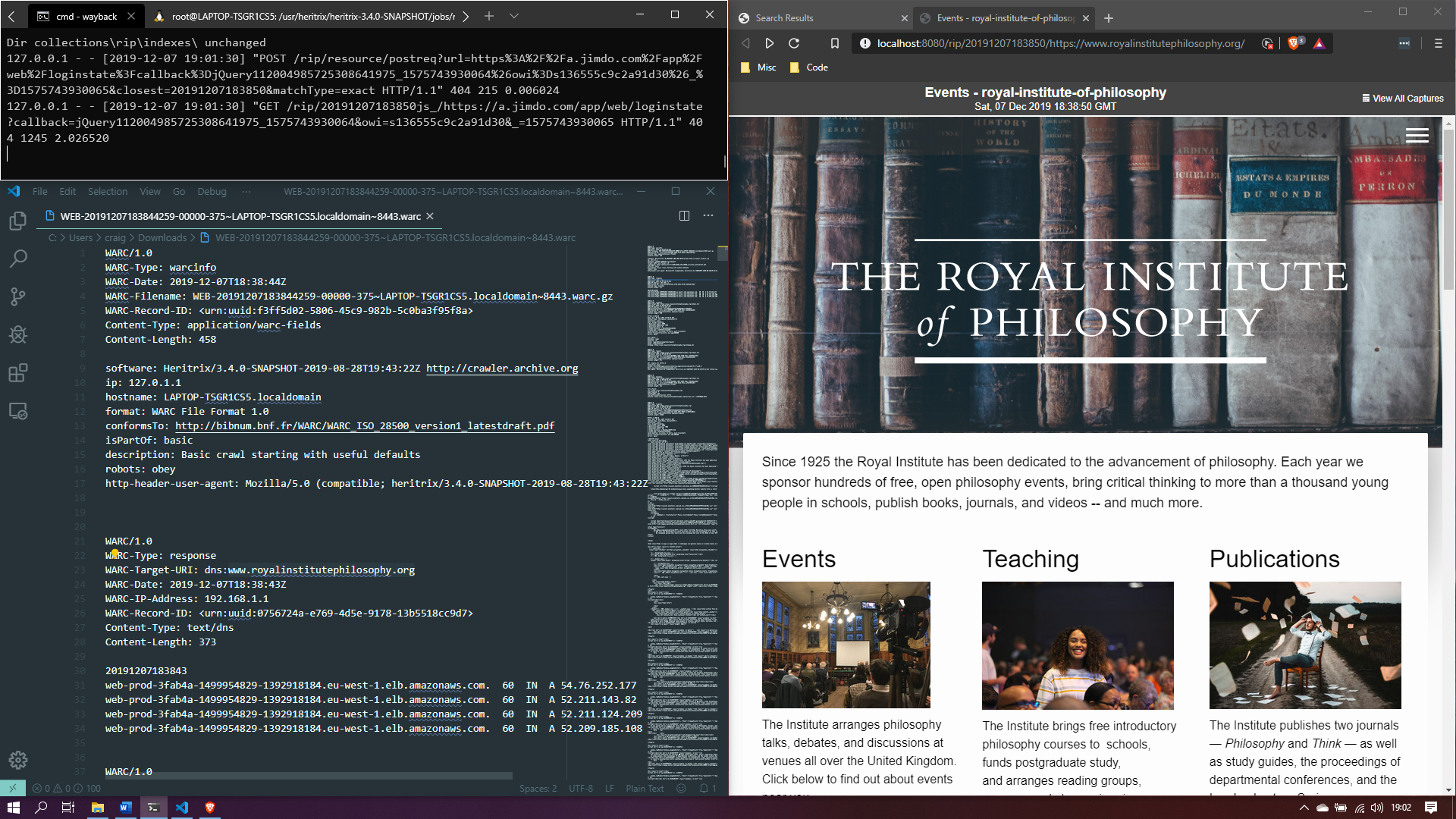
I took a closer look at the WARC file using the Archives Unleashed Toolkit. This in itself meant installing Apache Spark and the Scala programming language.
The Archives Unleashed Toolkit seems pretty powerful, it allows you to do all sorts of stuff like -
-
Collection Analytics
-
Plain Text Extraction
-
Raw HTML Extraction
-
Named Entity Recognition
-
Analysis of Site Link Structure
-
Image Analysis
-
Filters
-
DataFrames
I had a go at making a network visualisation of the website that I captured using an export from the Archives Unleashed Toolkit straight into Gephi - it looked very pretty. Unfortunately, I forgot to save/take a screenshot of it 😢